Implement an ETL solution that supports incremental data loading
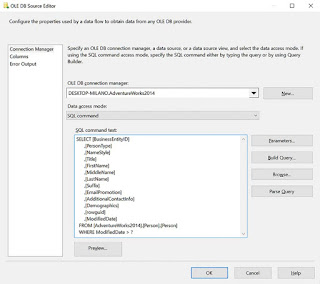
Design a control flow to load change data In creating an incremental load Data Flow, you can create a dynamic query within the OLE DB Source Editor under Connection Manager page, go to the Data Access Mode drop-down and select SQL Command. This opens up a free text pane below labeled SQL Command Text. Here we can enter the query against the source table with a variable parameter in the WHERE clause. The parameter is identified by the “?” in the SQL text. “?” is the syntax used by the SSIS expression language for a parameter. With the SQL query in place, click the Parameters button to map the SQL query parameter to the SSIS variable @LastModifiedDate, which will pass in the value of MAX(ModifiedDate) from the fact table. Make sure the Param Direction is set to Input because the SSIS variable value is being passed in to be used by the query. Load data by using Transa...


