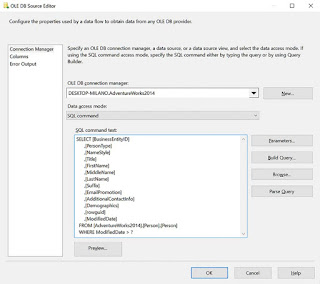
Clean data by using the SSIS DQS task

SQL Server Integration Services (SSIS) includes a DQS Transformation to correct data from a connected data source. The DQS Transformation Output column is populated with one of five status as listed below. You can use a Conditional Split Transformation to separate out the output records based on its status. You can apply different business logic to each stream or insert them to a table of file destination for manual processing. To clean data using the SSIS DQS task follow these steps: Open a new SSIS package in Visual Studio Create a new Data Flow Task Add a Source Component to extract the data to be cleansed Add a DQS Cleansing transformation and connect it to the Source Component Output Edit the DQS Cleansing transformation and set the Data Quality connection manager and Data Quality Knowledge Base to use for the cleansing activity Click on the Mapping tab and map the Input Columns to the corresponding Knowledge Base Domain, then click OK Add a C...